IPS (Indoor Positioning System) 등장배경
자동차를 운전할 때 필수기기가 되어버린 네이게이션, 요즘은 네비게이션 단말기도 한물 가버렸고
지금은 스마트폰이 그 역할을 한지 오래되었는데, 이 네이게이션의 핵심 기능이 바로
GPS(위성위치확인시스템) 이다. 위성과 통신을 해서 내 차 (정확하게 말하면 스마트폰) 의 위치를
인식하는 시스템인데 이 GPS의 가장 큰 단점은 위성신호를 받지 못하는 실내에서는 작동이
안 된다는 것이다.
IPS는 WiFi, 블루투스,Beacon, 자기장 등을 이용하여 건물 내부에 있는 사용자의 위치를 파악하고, 이를
스마트폰에 내장된 지도와 대조해 물건이나 장소의 위치를 쉽게 찾아주는 시스템으로서
‘실내 내비게이션’이라고도 한다
(참조 : [네이버 지식백과] IPS[Indoor Positioning System] - 실내 위치 확인 시스템, 실내 위치 측위
시스템 (지형 공간정보체계 용어사전, 2016. 1. 3., 이강원, 손호웅)
더군다나 최근 지속적인 무선통신 및 인터넷의 폭발적인 성장은 사용자의 모빌리티를 크게 강화시켰고,
특히 2007년 애플사의 아이폰의 등장과 함께 무선통신, GNSS, 카메라, 관성센서 등이 결합된 스마트폰의
보급 확대를 통해 이동 단말의 위치 인식 범위가 확대되고 위치 장확도가 정차 향상되고 있는 추세이다
([출처] 사용자 참여 기반 실내 위치인식 플랫폼 기술|작성자 센서로세계로미래로)
IPS의 특징
| 특징 | 설명 | 관련사례 |
| Device Mobility 확장 |
사용자가 실외에서 실내로 이동 시 Beacon 신호 송수신 을 통해 실시간 위치기반서비스(LBS) 제공 가능 |
애플의 iBeacon CSR의 SiRFusion 제품 |
| 실내외 네트워킹 연계 |
인공위성의 GPS 신호를 삼각측량한 정보와 인접한 Cell-ID 정보를 결합하여 높은 수준의 위치측정 |
실내외 참조포인트 무선WPS |
| 산업간 융복합 플랫폼 구축 |
공장, 쇼핑몰 등에서 센서 부착한 로봇, 사용자의 이동 경로를 추적하여 서비스 모니터링 및 공급망 관리 수행 |
물류로봇 스마트팩토리 |
| 다양한 사용자 경험 제공 |
스마트폰, HMD 기기와 연계하여 현실세계와 가상세 계가 유기적으로 결합된 향상된 UX/UI 제공 |
AR, VR게임 옴니채널, O2O |
< 출처 : 정보관리기술사 118회 모임 - 두드림 >
비콘 (Beacon) 을 이용한 위치측위기술
| 구분 | 설명 |
| 체크포인트 (Check Point) 방식 |
비콘(Beacon) 1대의 신호를 받아서 그 위치를 통과한 경우 그 대상물이 그 위치를 통과한 정보를 기록하는 것으로 RFID태그가 RFID 리더를 통과했을 때의 위치정보를 확인하는 방식이다. |
| 존 (Zone) 방식 | 비콘(Beacon) 1대 혹은 여러 대가 신호 범위별로 배치되어 있고, 대상물이 특정 비콘 주변에 놓여 있을 때, 그 비콘 위치 주변에 있다는 정보를 기록하는 것대부분의 BLE (Bluetooth Low Energy) 비콘이 이 방식을 사용 |
| 실시간 위치 (Track) 방식 |
여러 대의 비콘이 실내에 신호 범위별로 배치되어 있고, 대상물이 3대 이상의 비콘으로부터 ID신호와 신호세기를 수신해 그 위치를 측위 알고리즘으로 계산, 위치를 파악하는 방식이다. 정확한 측위 알고리즘을 위한 AOA(Angle of Attach), ROA, Finger Print, TDOA(Time Difference of Arrial), TOA(Time of Arrival) 등의 기술이 있으며, 실외에서 사용하는 GPS도 3개 이상의 위성으로부터 오는 신호를 삼각측량 방식으로 계산한다 |
Radio 기반 IPS 측위 기술
| 구분 | 측위 기술 | 설명 |
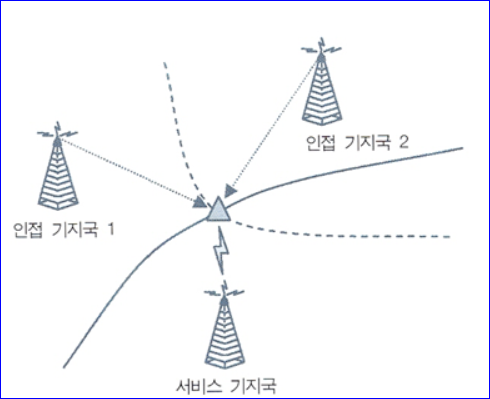
| 기지국 기반 | Cell-ID | 기지국에서 위상, 전계강도 정보 받아 측위서버 전송 셀의 전파세기 측정하여 구축DB의 유사패턴매칭 |
| Fingerprint | 실제환경에서 위치별로 RSSI (Received Signal Strength Indicator)값을 측정하여 테이블 생성 기존에 구축된 전파맵과 수신한 비콘 신호를 비교 |
|
| 삼각측량법 | 3개 이상의 기준점과 한 점과의 거리를 통해 좌표 측정 기준점과의 거리를 반지름으로 하는 원을 그려 교점 탐색 Wi-Fi환경에서는 AP를 기준점으로 상대적 거리 계산 |
|
| WLAN 기반 | WPS | 무선AP의 SSID와 MAC주소를 주요 파라미터로 활용 핑거프린팅방식으로 GPS가 지원되지 않는 영역에서 측위 |
| RSSI | 센서로부터 전압레벨을 측정하여 실내위치 측위 무선주파수 내에서 송수신된 전력으로 거리 측정 |
|
| WPAN 기반 | UWB | UWB 단말에서 고유ID를 32bit로 송출 광대역주파수를 활용하여 뛰어난 투과력과 고속성 제공 * UWB(Ultra Wide Band) 협대역 시스템 및 3G 셀룰러 기술로 설명되는 광대역 시스템과 구분하기 위해 중심 주파수의 20% 이상의 점유대역폭을 차지하는 시스템이나 500MHz 이상의 점유대역폭을 차지하는 무선 전송 기술을 말함. (500Mbps의 고속 전송이 가능) |
| Zigbee | ZigBee 탑재단말이 AP통해 단말위치 전송 저전력성 제공 및 다수 노드와 클러스터링 용이 |
|
| Bluetooth | Bluetooth 4.0, iBeacon 사용, 최대 50m까지 전송 가능 블루투스 AP 활용하여 지오펜싱 기반의 전파맵 생성 |
< 출처 : 정보관리기술사 118회 모임 - 두드림>
Non-Radio 기반 IPS 측위 기술
| 구분 | 측위 기술 | 설명 |
| 센서기반 | 자기장센서 | 스마트 폰 자기장 센서 센서로 측정하여 미리 입력된 건물 내부 자기장 지도와 비교해 길을 안내 |
| 관성센서 | 단말기 내 관성센서(가속도,방향계 등) 이용하여 측위 - 실내의 특정 기준점을 근간으로 상대적인 위치 측위 |
|
| LED | 실내 LED 조명마다 식별번호 부여하고 스마트폰이 감지 - 식별번호를 데이터베이스와 대조해 현재 위치를 파악 |
|
| 주파수기반 | RFID | RFID Tag로 Bluetooth, WiFi등의 전송망을 이용하여 서비스 제공 - Tag의 위치 정보 수집 및 분석에 별도의 서버 필요 |
| 적외선 | 실내 곳곳에 부착된 적외선 센서가 고유 ID 코드를 가진 적외선 장치를 인식하여 위치를 찾아내는 방식 - 디바이스 내부에 IrDA 컨트롤러 탑재필요 |
|
| 초음파 | 스마트폰으로 초음파를 발사해 벽에 부딪혔다가 반사되는 것을 포착해 위치와 건물내부의 형태 파악 | |
| 영상기반 | 비주얼 마커 | 모바일의 카메라로 위치좌표를 디코딩하여 실내위치 결정 - 라이더, 스테레오 카메라로 주변 공간의 좌표 정보와 특징점 정보를 추출하여 3차원의 공간정보 DB화 |
| CCTV기반 | CCTV 실시간 영상, 이미징 정보를 기반으로 상대측위 최근 고해상도 CCTV 출시로 실내 및 실외감시 서비스 |
< 출처 : 정보관리기술사 118회 모임 - 두드림>
IPS 활용 서비스 고도화 방안

'디지털서비스' 카테고리의 다른 글
| 시맨틱웹(Semantic Web) 구축을 위한 Linked Open Data (LOD) :1탄 (0) | 2019.10.26 |
|---|---|
| 근거리 무선 통신 기술 (0) | 2019.10.18 |
| LBS (Location Based Service) 측위 기술 (0) | 2019.10.16 |
| 디지털 트윈 (Digital Twin) (0) | 2019.10.10 |
| R 과 Python 의 비교 (0) | 2019.09.25 |