728x90
반응형
SMALL
비정형 데이터란?
형식이 정해지지 않은 데이터. 데이터는 형식이 정해진 정형 데이터(formal data)와 형식이 정해지지 않은 비정형 데이터가 있다. 페이스북, 트위터 등 소셜 네트워킹 서비스(SNS, 누리소통망 서비스)의 확산으로 데이터베이스에 잘 정리된 데이터가 아닌, 웹 문서, 이메일, 소셜 데이터 등 비정형 데이터가 주를 이루고 있다.
[네이버 지식백과] 비정형 데이터 [informal data, 非定型-] (IT용어사전, 한국정보통신기술협회)
비정형 데이터 마이닝의 개념
비정형 데이터를 정련 과정을 통해 정형 데이터로 변환하고 분류, 군집화, 회귀분석, 이상탐지 등의 기법으로
유의미한 정보를 추출하는 기법
비정형 데이터 마이닝의 유형
| 유형 | 설명 |
| 텍스트 마이닝 | 자연어 처리 방식을 이용한 정보추출 기법으로 특정 키워드나 문맥을 기반으로 의미를 추출하는 분석기법 |
| 오피니언 마이닝 | 소셜 미디어에서 긍정/부정/중립을 구분하여 선호도를 판별하는 기술로 분석 대상인 키워드로 빈도수를 측정하는 분석 기법 |
| 사회연결망 분석 | 소셜 네트워크 서비스에 내포된 사용자간의 관계를 분석하는 기법 |
| 군집 분석 | 변화가 많은 대상 집단을 일정한 군집으로 나눠 특성을 분석하고 타 집단과의 지리를 관측하기 위한 분석기법 |
사회연결망 분석의 개념
| 설명 | |
| 개념 | 개인과 집단들 간의 관계를 노드와 링크로서 모델링해 그것의 위상구조와 확산 및 진화과정을 계량적으로 분석하는 기법 |
| 개념도 | 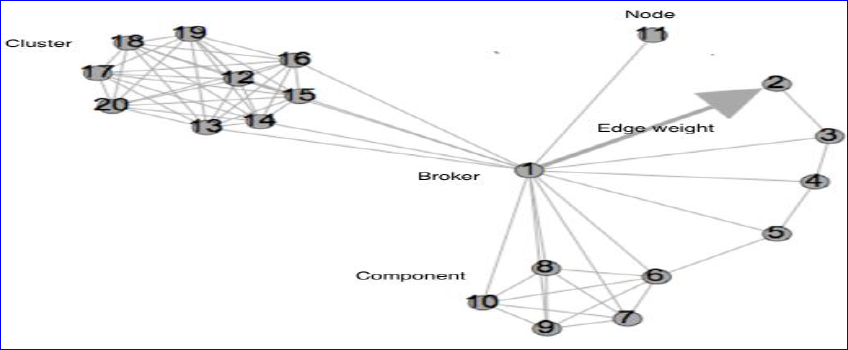 |
사회연결망 분석 표현 방법
| 구분 | 설명 | |
| 집합론적 방법 | 집합 X={X1} 관계 쌍 A,B A={(X1, X2), (X2, X1),(X4, X2),(X3, X1) } B={(X1, X2), (X2, X1), (X3, X4),(X4, X3 } |
각 객체들의 관계를 관계쌍으로 표시 |
| 그래프 이용방법 |  |
객체는 노드, 객체간 연결망은 선(Edgee)으로 표현 |
| 행렬 이용 방법 |  |
각 객체를 행렬의 행과 열에 대칭적 으로 배치 |
사회연결망 분석 기법
| 분석기법 | 유형 | 설명 |
| 중심성 (Centrality) |
연결정도 중심성 (Degree) |
- 한도드에 직접적으로 연결된 노드 합으로 얻어진 중심성 - 노드가 중심에 위치하는 정도를 계량화 - 링크에 방향성이 있는 경우 in-degree (내향성), out_degree(외향성) 로 분류 𝐶′𝐷(𝑖)=𝐶𝐴(𝑖)/𝑛-1 ,n:네트워크 내 전체 노드 수 |
| 근접(인접) 중심성 (closeness) |
- 간접적으로 연결된 모든 노드 간 거리 합산한 지표 𝐶′𝑐(𝑖)=(𝑛−1)𝐶𝑐(𝑖) |
|
| 매개(사이) 중심성 (Betweeness) |
- 매개자 혹은 중재자 역할의 정도를 측정한 지표 𝐶′𝐵(𝑖)=𝐶𝐵(𝑖) / (n−1)(n−2)/2 |
|
| 위세 중심성 (Elgevector) |
- 연결된 노드의 중요성에 가중치를 부여한 지표 | |
| 밀도 (Density) |
연결정도 (Degree) |
- 한 노드와 직접적으로 연결된 노드들의 수 |
| 포괄성 (Inclusiveness) |
- 한 연결망 내에 서로 연결된 행위자들의 수 - 한 연결망의 전체 노드수에 격리된 점들의 수를 제외하고 남은 수로 계산 |
|
| 중심화(집중도) (Centralization) |
연결정도 (Degree) 근접, 중개 중심화 |
- 네트워크 전체 연결망의 형태가 중앙에 집중된 정도를 분석 |
728x90
반응형
LIST
'디지털서비스' 카테고리의 다른 글
| 스마트 그리드 (Smart Grid) (0) | 2019.12.14 |
|---|---|
| 비정형 데이터 마이닝 - 텍스트 마이닝 (0) | 2019.12.02 |
| 클라우드 (Cloud) 컴퓨팅의 정의 및 필요성 (0) | 2019.11.16 |
| 멀티 모달 인터페이스 (Multi Modal Inferface) (0) | 2019.11.08 |
| 시맨틱웹(Semantic Web) 구축을 위한 Linked Open Data (LOD) :2탄 (0) | 2019.10.27 |


