Apriori 알고리즘을 이용한 연관규칙 도출방법을 보면 빈발항목중에서 후보집합을 선정하는 기준으로
지지도(Support) 를 사용한다. 이처럼 연관규칙분석을 할ㅣ때 후보집합을 결정하려면 먼가 후보선정/탈락
측정기준이 있어야 하는데..주로 쓰이는게 3가지 기준이 있다.
| 측정기준 | 설명 | 수식 |
| 지지도 (Support) |
전체 거래중에서 품목 A와 B가 동시에 포함된 거래의 수 예) 마트에서 고객이 구매한 거래내역중에서 빵과,우유를 동시에 구매한 거래 건수 우유,빵 모두 포함된 거래 (A∩B) Support = ----------------------------------- 전체 거래수(N) |
A∩B A∩B / N = ------ N |
| 신뢰도 (Confidence) |
품목 A가 구매되었을 때 품목 B가 추가로 구매될 확률 (조건부 확률) 우유,빵 모두 포함된 거래 (A∩B) Confidence = ---------------------------------- 우유가 포함된 거래수 (A) |
A∩B A∩B / A = ------ A |
| 향상도 (Lift /Improvement) |
품목 A를 구매할 때 B도 구매하는지 서로 간의 연관성을 파악하는 비율 우유.빵 모두 포함된 거래수 -------------------------------- 전체거래수 Lift = -------------------------------------------------------- 우유가 포함된 거래수 빵이 포함된 거래수 ---------------------- X ---------------------- 전체거래수 전체거래수 우유.빵 모두 포함된 거래수 x 전체거래수 = --------------------------------------------- 우유가 포함된 거래수 x 빵이 포함된 거래수 A∩B x N = ------------- A x B > 1 이면 양의 상관관계 = 1 이면 독릭접인 관계 < 1 이면 음의 상관관계 |
A∩B x N ------------ A x B |
예제
문제) 우유와 빵을 함께 구매한 거래가 10%이고,우유를 구매한 거래의 20%가 빵도 구입했을 때
우유->빵의 상관관계는 ? (전체거래중 빵을 구입한 거래는 10%이다)
(풀이) 상관관계란 향상도를 뜻한다. 향상도가 > 1 이면 양의 상관관계이다.
만약 전체거래(N) = 10 이라고 가정하면
지지도 = 10% = 1/10 즉 우유,빵 함께 구매한 거래가 1건
신뢰도 = 20% = 1/우유 구매수 즉 우유 구매수 = 5 건
빵구입이 10% 이므로 즉 빵 구매수 = 1건
우유.빵 거래수 X N 1 x 10
향상도 = ------------------------- = -------- = 2
우유거래수 x 빵거래수 5 x 1
Apriori 알고리즘 설명
Apriori알고리즘은 지지도를 이용해서 연관규칙을 찾는 기법중에 하나이다.
- 연관규칙를 찾아주는 알고리즘 중에서 가장 먼저 개발되었고, 또 가장 많이 사용된다.
- 연관성규칙의 첫 번째 단계는 항목들 간의 연관성을 나타내기 위한 후보가 되는
모든 규칙들을 생성
- 구매 데이터베이스 내에서 단일 항목들, 2개로 된 항목들, 3개로 된 항목들. 기타 등등의
모든 조합을 발견
- 그러나 항목들이 늘어나면 이러한 모든 조합들을 생성하기 위한 계산시간은 기하급수적으로
증가함.
- 데이터베이스 내에서 높은 빈도를 갖는 조합 (빈발 항목집합 : Frequent item sets) 을
찾아내는 것
- 빈발 항목집합 결정 도구 :지지도(Support)
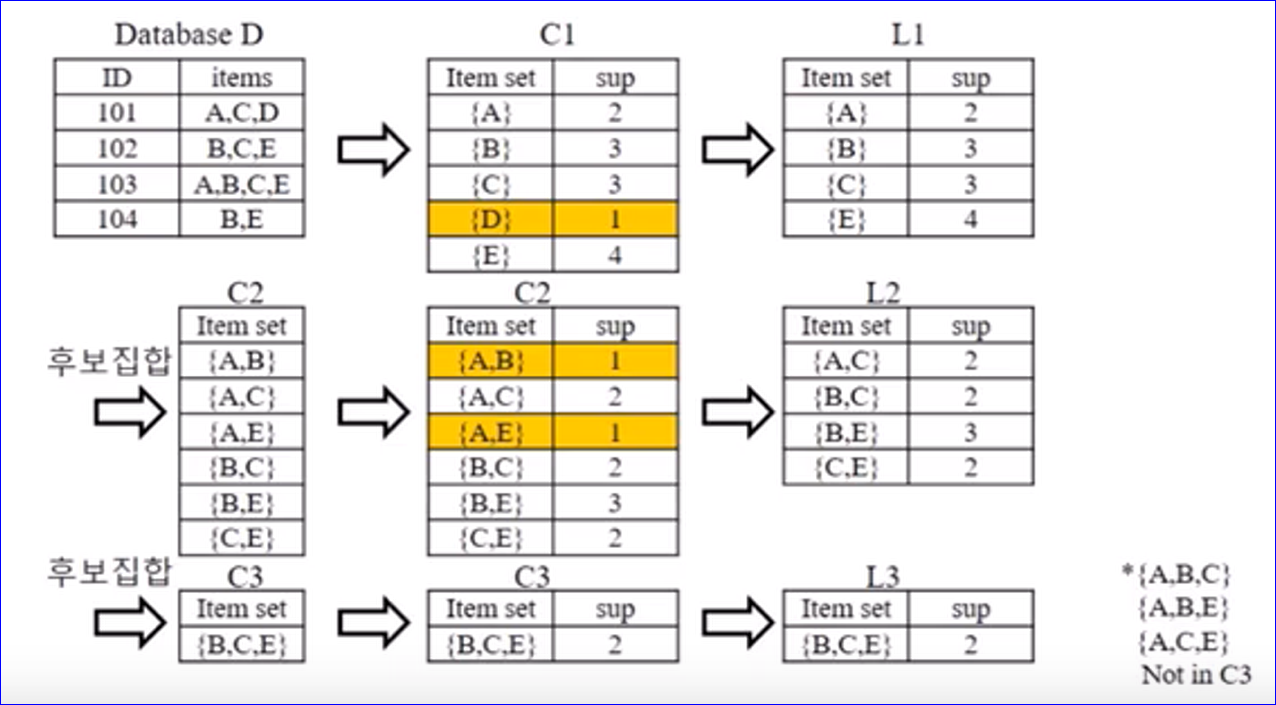
위 그림에서 ID 101,102... 가 고객번호라고 생각하고 그 고객이 구매한 상품들이 items 이라고 하자.
[1단계] 단일항목 즉 단일항목 기준으로 해서 구매 빈도수(sup/지지도)를 구해보면 A 항목은 101, 103 고객이
구매했으니깐 2 이고, B항목은 3, C항목도 3 ... 이런식으로 구매된 횟수를 카운트 한 결과가 C1 이다.
이때 기준 횟수를 2 즉 구매횟수가 2미만인 항목은 제외를 한다 라는 기준을 세운다. (최소 지지도)
이 기준에 의하면 C1 테이블에서 제외할 항목은 구매횟수가 1인 D 항목이고 D 항목을 제외한 새로운
후보집합 L1 을 도출할 수 있다.
[2단계] L1 후보집합을 기준으로 2개항목 조합을 해서 구매빈도수 즉 지지도를 구한다.
그러면 C2 테이블을 만들 수 있다. 이 조합중에서 최소지지도인 2를 충족하지 못하는 (A,B) , (A,E) 조합을
제외하면 L2 라는 새로운 후보집합을 도출할 수 있다
[3단계] 마찬가지로 L2 후보집합을 기준으로 이번에는 3개항목을 조합해서 구매빈도수(지지도)를 구해본다.
(A,B,C) , (A,B,E), (A,C,E) ,(B,C,E) 조합이 나올수 있는데 이때 2단계에서 최소지지도에 못미쳐서 제외된 조합이
(A,B), (A,E) 였기 때문에 (A,B,C) , (A,B,E), (A,C,E) 조합들에서 (A,B), (A,E) 조합이 부분집합으로 포함된 건
제외해야 하기 때문에 결국 (B,C,E) 조합만 남게 된다.
(B,C,E) 조합의 지지도를 구해보면 2 가 되고 이는 최소지지도를 충족하므로 후보집합이 될 수 있다.
'데이터베이스' 카테고리의 다른 글
| 데이터사이언스 (Data Science) - 빅데이터(Big Data) 분석 (0) | 2019.10.12 |
|---|---|
| 오픈소스 DB (0) | 2019.10.11 |
| 연관규칙 : Apriori 알고리즘 - 지지도 (0) | 2019.09.27 |
| 데이터베이스의 연관규칙(Association Rule) 분석 (2) | 2019.09.26 |
| 데이터베이스 Isolation Level (고립수준) (1) | 2019.09.24 |